5.9 stacking算法基本思想
1 集成学习基本复习
Ensemble learning 中文名叫做集成学习,它并不是一个单独的机器学习算法,而是将很多的机器学习算法结合在一起,我们把组成集成学习的算法叫做“个体学习器”。在集成学习器当中,个体学习器都相同,那么这些个体学习器可以叫做“基学习器”。
个体学习器组合在一起形成的集成学习,常常能够使得泛化性能提高,这对于“弱学习器”的提高尤为明显。弱学习器指的是比随机猜想要好一些的学习器。
在进行集成学习的时候,我们希望我们的基学习器应该是好而不同,这个思想在集成学习中经常体现。
- “好”就是说,你的基学习器不能太差,
“不同”就是各个学习器尽量有差异。
集成学习有两个分类,一个是个体学习器存在强依赖关系、必须串行生成的序列化方法,以Boosting为代表。另外一种是个体学习器不存在强依赖关系、可同时生成的并行化方法,以Bagging和随机森林(Random Forest)为代表。
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。
上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。
2 stacking 的基本思想
stacking 就是将一系列模型(也称基模型)的输出结果作为新特征输入到其他模型,这种方法由于实现了模型的层叠,即第一层的模型输出作为第二层模型的输入,第二层模型的输出作为第三层模型的输入,依次类推,最后一层模型输出的结果作为最终结果。本文会以两层的 stacking 为例进行说明。
stacking 的思想也很好理解,接下来我们首先看两个简单的举例:
举例一:以论文审稿为例,首先是三个审稿人分别对论文进行审稿,然后分别返回审稿意见给总编辑,总编辑会结合审稿人的意见给出最终的判断,即是否录用。对应于stacking,这里的三个审稿人就是第一层的模型,其输出(审稿人意见)会作为第二层模型(总编辑)的输入,然后第二层模型会给出最终的结果。
举例二:A、B是学习器,C、D、E是进行答案再组织的次学习器,次学习器会组织利用底层模型提供的答案。

stacking 的思想很好理解,但是在实现时需要注意不能有泄漏(leak)的情况,也就是说对于训练样本中的每一条数据,基模型输出其结果时并不能用这条数据来训练。否则就是用这条数据来训练,同时用这条数据来测试,这样会造成最终预测时的过拟合现象,即经过stacking后在训练集上进行验证时效果很好,但是在测试集上效果很差。
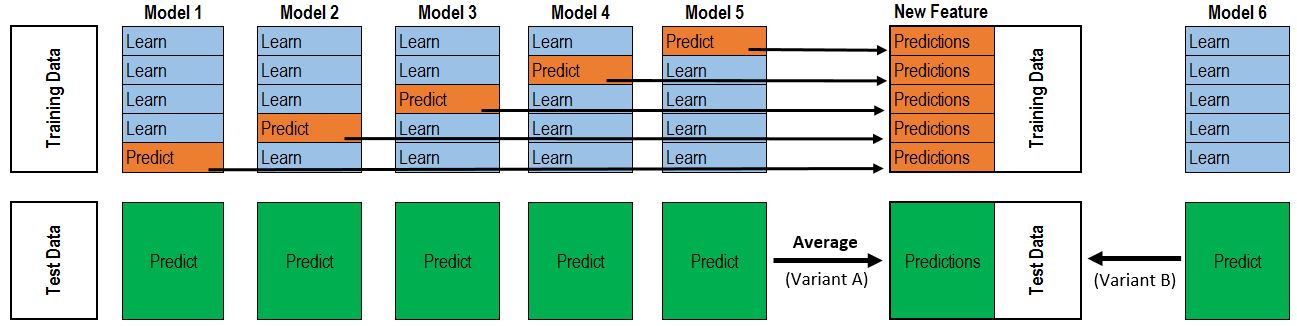
为了解决这个泄漏的问题,需要通过 K-Fold 方法分别输出各部分样本的结果,这里以 5-Fold 为例,具体步骤如下
(1) 将数据划分为 5 部分,每次用其中 1 部分做验证集,其余 4 部分做训练集,则共可训练出 5 个模型 (2) 对于训练集,每次训练出一个模型时,通过该模型对没有用来训练的验证集进行预测,将预测结果作为验证集对应的样本的第二层输入,则依次遍历5次后,每个训练样本都可得到其输出结果作为第二层模型的输入 (3) 对于测试集,每次训练出一个模型时,都用这个模型对其进行预测,则最终测试集的每个样本都会有5个输出结果,对这些结果取平均作为该样本的第二层输入
上述过程图示如下
除此之外,用 stacking 或者说 ensemble 这一类方法时还需要注意以下两点:
- Base Model 之间的相关性要尽可能的小,从而能够互补模型间的优势
- Base Model 之间的性能表现不能差距太大,太差的模型会拖后腿
3 stacking的特点
使用stacking,组合1000多个模型,有时甚至要计算几十个小时。但是,这些怪物般的集成方法同样有着它的用处:
(1)它可以帮你打败当前学术界性能最好的算法
(2)我们有可能将集成的知识迁移到到简单的分类器上
(3)自动化的大型集成策略可以通过添加正则项有效的对抗过拟合,而且并不需要太多的调参和特征选择。所以从原则上讲,stacking非常适合于那些“懒人”
(4)这是目前提升机器学习效果最好的方法,或者说是最效率的方法human ensemble learning 。